Picture a node
A node in a doubly linked list can be pictured like this:
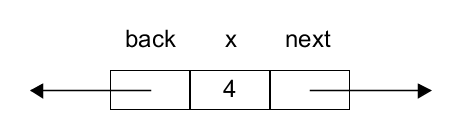
This emphasizes that a node contains three fields. But it is a bit too detailed to use often.
The coursework this week counts 25% towards your credit for the unit. The main purpose is to practice using pointers.
If you are still using Windows, you will be at a big disadvantage because (a) it will be very difficult for you to track down segfaults and (b) your program may work for you, but bugs may show up when we use the advanced debugging options, so you may lose marks.
Your task is to write a reusable library module for doubly linked lists. You are provided with these files:
list.h file is the APIThe header
file lists.h forms its API,
which you should not change, but which you should read carefully because the
comments describe what the functions do:
list.c file has no skeletonsThis time, skeleton versions of the functions are not provided, just tests.
An atempt to compile the program will fail, at the moment.
The header is set up to store int values in lists, but
item is used as a synonym for int everywhere, so that
there is only one place where a change would need to be made to store some other
type of items.
This means the module can be used with different item types in different programs, but it is not truly generic. It cannot be used multiple times for different item types in the same program. There is no really satisfying way of making fully generic modules in C.
It is recommended, as a last test before submitting, that you change the item
type to double, to check that you haven't inadvertently
assumed int anywhere. (The numbers used in the tests should still
work as doubles.)
The header doesn't say that the list is to be doubly linked. That's because a user of the module need not know or care, and the implementation could be changed to something completely different in a later version of the module, without any effect on programs that use it.
On the other hand, the header does say that all the operations are constant
time. This is a strong hint that the implementation does use a doubly linked list
or something similar, because it is difficult to achieve constant
time operations otherwise. As a matter of fact, a flexible circular gap buffer
could work and
would probably be superior, but you aren't allowed to do that, because you need
the pointer practice!. The claim of constant time doesn't cover the vagueness in
the time taken by malloc and free calls but,
conventionally, memory management costs are considered separately from the
'logic' costs of operations.)
The function names use the camel case convention, where capitals make the letters go up and down like the humps on a Bactrian camel. The most common alternative is snake case using underscores.
I should point out, for those who are interested, that including a current position in the list structure itself is not thread safe. A more thread-safe approach is to create a separate iterator object each time the list is traversed. However, that approach can still easily lead to 'concurrent modification' problems where the list structure is changed by one thread while another is traversing it. It is much safer to make sure that a list is owned by a single thread.
Pointer programming is notorious in C for causing segfaults and similar problems. The best approach for using them in ordinary applications is to put all the pointer code into separate modules, each with an opaque type and a suitable API like this list module, make sure that other modules and programs are insulated from the details, and make full use of the advanced debugging options.
Your first task is to turn lists.c into a full skeleton program
that compiles. You can do this without fully understanding the assignment.
Include a line #include "lists.h" and also include any
standard headers which you think you are going to need.
You need to define a structure for the nodes which make up the list, and a structure for the list itself.
The node structure is not visible to the user of the module. It is used to
store each item and the two links (next and back, say)
which define the list ordering. The structure isn't really needed in the
skeleton, so you can leave it out or define a temporary version.
The purpose of the list structure struct list is so that
newList can return
something to the user which never changes, and which holds information about the
list as a whole. You can define a temporary version for now.
Write a minimal dummy definition of each of the functions mentioned in the header file.
The safest way to do that is to copy-and-paste a function's declaration from
lists.h, then replace the semicolon by
curly brackets. If the function returns anything other than void,
add a return statement which returns the easiest temporary value of that type
you can think of (e.g. NULL for a pointer, false for
a boolean).
For functions returning an item, you can return 0 for now,
but beware that depends on item being int, so
it will need to be fixed later.
At this point, check that the program compiles.
There are not many programmers who can program with pointers without using pictures. There is usually nothing better than scribbling on paper or a whiteboard to sort out the ideas. Here are some pictures to help with this assignment:
A node in a doubly linked list can be pictured like this:
This emphasizes that a node contains three fields. But it is a bit too detailed to use often.
For most purposes, you can simplify like this:

The pointer fields are implicit.
Iterating through a list is like iterating through an array. With an array of
length two, the index iterates through 0, 1 and
2, with 2 indicating the end of the loop. The indexes
are thought of in two ways. Either an index 'points to' an item (with
2 as an exception) or it can be thought of as between items, with
0 referring to the start of the array and 2 referring
to the end.
Similarly, with a linked list of length two, there needs to be three possible possible positions. You can think of a position as pointing to an item (with the exception of the end position), or as pointing between items (with the end position being after the last item).
The current position in the list is going to be a pointer which points to a
node. That means an extra end node is needed to represent the position at the
end of the list. So a list with two items 3 and 7 has
three nodes like this:
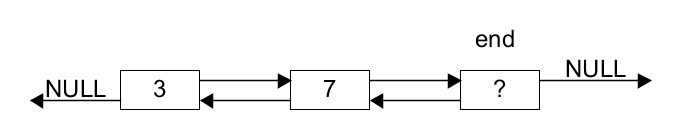
The next pointer of the end node, and the back
pointer of the first node are NULL. The list structure will
contain a current pointer, pointing to one of these three nodes. The item
value in the end node is never going to be used, so it can be left
uninitialized, or set to anything convenient.
Note: just because I have used arrays to explain what happens in a list, that does not mean that a list needs to keep track of an index or a length.
It is easy to see how the functions are going to be constant time, except for
startF and startB. To make those constant time,
the list structure itself needs to keep pointers to the first node and the last
node.
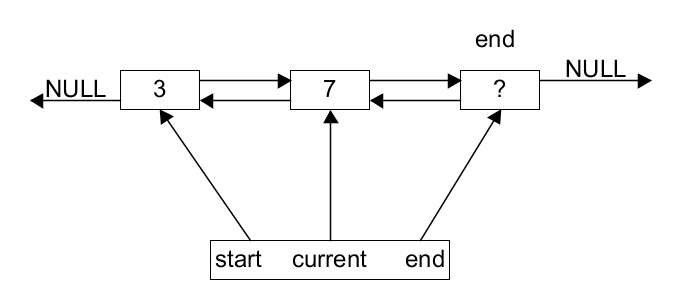
The list structure contains three pointers.
There is no problem with the pointer to the end node, because the end node never changes. But the pointer to the first node has a couple of problems.
When a new item is inserted before the first item of the list, the first node changes, so the list's pointer to the first node needs to be updated.
Also, when the insertion is done, the code has to be different from other insertions, because there is no previous node before the current one.
These are problems which can be solved, but they complicate the code. Is there another way?
One way to make things smoother is to add another node before the first node. This is sometimes called a sentinel, but let's call it the pre node. (Don't call it 'first', because it is before the first node.)
The list structure points to the pre node instead of the first node. The pre
node never changes, and the first node can always be found as
pre->next. Inserting before the first item can use identical code
to any other insertion.
It turns out, since it is only the next pointer that is needed
in the pre node, that the end node can be used as the pre node. This saves
memory, but may make the freeList function slightly more
complex.
It is completely up to you whether you want to add an extra pre node, or use the end node as a pre node. And the user of your module should not be able to tell which decision you have made.
insertFTo visualize what a function does, draw a picture of the situation before the call, and another of the situation after.
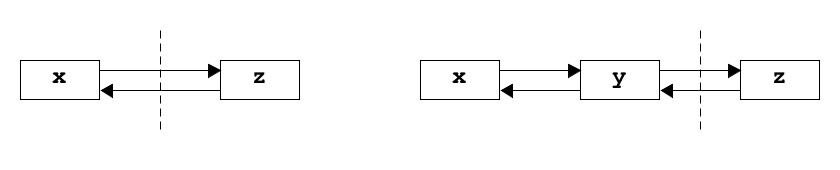
A dotted line shows the current position, between two nodes (though it would
in reality be a pointer to the z node). In the code for insertF,
as well as creating and filling in the y node, the pointers x->next
and z->back need to be updated.
The tests are a bit unusual. One reason is that you haven't been given a skeleton which includes the structures. That means the tests can't check the structure fields, which could be different for each of you. Instead, they have to be based around calls to the list functions, and nothing else, as if the module were being tested from the outside.
Some of the functions need to check that the call is legal. If that were done
with assert or something similar, it wouldn't be possible to test
that it was being done properly. So, the functions are designed to return
something even if the call was illegal. For example, nextF moves to
the next item in the list, but is not legal when the list is at the end. In that
case, it does nothing and returns false, which is easy to test.
The getF function returns an item. But it is not legal when the
list is at the end. To make sure it can be tested, it needs to return something,
even in that case. But it can't return -1 for example, because
item might not be int. To make sure there is an item
which can be returned in case of error, the newList function is
passed a default item. That item d should be stored in a field of
the list structure, and used in these illegal cases. The default value can then
be used in testing.
Following the pattern of this unit, every test is on one line using
assert. Here's an example:
assert(check("startF", "3|7", "|37", 0, 0, true));
To describe lists as compactly as possible, strings are used. The string
"3|7" describes a list with two items 3 and
7 where the current position is in between the items (or pointing
at the 7 if you prefer, but that makes it more difficult to express
the symmetry between F and B functions, for example). The test checks that if the
startF function is called on a list like that, the result is
"|37", i.e. the current position is moved to the start, but
otherwise the list is not changed.
What does each function do? There is a comment in the lists.h
header which gives an intuitive summary, but it doesn't tell you exactly what
happens in every case.
For each function, there are four tests, which show precisely what the
function does on the empty list "|" and a list with two items in
each of the three cases "|37" and "3|7" and
"37|". That should be enough for you to work out what the function
does in every possible case.
To make the functions work, there is a function toList which
converts a string like "3|7" into a list, and a function
toString which converts a list back into a string. Also, there is a
function check which checks a given function, handling all the
details so that each test can be on one line.
A drawback of this testing strategy is that each test needs quite a large number of the list functions to be working. So a couple of tests have been added to illustrate tests that you could add for yourself, commenting out the others, while you are getting started.
The approach taken here to testing is one I use quite commonly. It has the advantage that the tests don't depend too heavily on the implementation choices being made, and therefore the tests are easy to maintain when programs are refactored. I hope you think that the tests and testing strategy are well designed. I am trying to illustrate that, in any project, design effort and ingenuity and creativity needs to go into the testing as well as the program.
Programming with pointers can be difficult, partly because it is impossible to create all the desirable types of test, partly because it is difficult to debug programs when things go wrong, and partly because it can be difficult to maintain an accurate mental model of what is going on. Programmers used to dread segfaults. That's where the new debugging options come in. If you misuse a pointer, there is a good chance that your program will be stopped, and you will get an error message with a line number to say where the problem is. This has made C a much more tolerable language. It is a pity that the options haven't fully made it onto Windows yet. Here's some practical advice:
The functions in this assignment may well be sufficiently small for you to be able to keep everything under control. But remember for the future, in any kind of project, that keeping functions tiny often has a huge reward.
The more exceptions and different cases your code handles, the more liable it is to have bugs in, because there are more places for bugs to hide, and it is harder for you to see at a glance that the code is correct
The possibility of using a pre node as a sentinel has been
mentioned. This is not a requirement, but it can help you to create a module
that works properly with minimum pain. With sentinels, none of the pointers in
your structures are ever NULL, so you don't need any special-case
checking for NULL pointers. Operations typically become very
simple, with no special cases to check for, even when the list is empty.
With care, you don't need any special-case checks for the sentinel nodes either, except for checking that an operation is valid, which you can do separately before you start manipulating pointers.
It is very tempting to write lines of code like this, with two or more arrows:
current->back->next = ...
The trouble is, this is very error-prone. The code may be written with a mental picture of where the nodes were at the start of the function, but one or more of the pointers used in the expression may have been changed already by the time this line is executed.
Trouble can arise particularly when shuffling lines of code around. A line of code that used to work may suddenly no longer work. And it is possible to 'lose' a node altogether, because there are no pointers left pointing to it, and therefore no way to reach it.
In this assignment, many of the functions can be said to involve 'left' and 'right' nodes, possibly with a 'middle' node being inserted or deleted between them. A good strategy is to set up local variables for these three nodes at the beginning of a function, so that you can keep track of them no matter what changes are made to the pointers between them. Each line of code can then be written using only one arrow, and the order in which the lines of code are executed is likely to matter less, making the code much more robust.
The F functions and B functions are mirror images of each other. But that is only from the user's point of view, and only if positions are regarded as pointing between items.
The code in an F function is not the mirror image of the code in the B function, because your list points at nodes, not between nodes. So, you need to think about each function carefully and separately.
On the other hand, functions can use other functions. Wherever you need to
check for an illegal situation, you might like to use endF or
endB rather than repeating pointer tests all over the place.
And once you have implemented insertF, maybe you can call it
from insertB rather then repeating the development pain.
If you do extra work this week, it is recommended that you do something else
with pointers, preferably involving trees. Implementing a search tree module,
or a tree-based map module, or a linked hash map module (look for descriptions
of Java's LinkedHashMap class), or writing a Huffman encoding
algorithm would be good examples.
The minimum is to submit lists.c. Marking will not just be by
how many tests you pass. Instead, if the tests don't all pass or the compiler
options show problems you haven't found, I will judge what your program is worth
by hand. So it would be quite helpful for you to submit a readme file to explain
your ideas. As always, also submit all the source code (including any headers)
and a readme for any extra work you have done.