This work tackles the problem of place recognition - can an autonomous system recognise a particular place in a city, for instance, based on vision alone? we assume that we have one or more images of locations over a wide area and the task is to recognise places based on new images taken at the same locations but from disparate views compared with those in the database. There has been considerable work on this in the past and if images are taken from similar viewpoints then algorithms exists which are able to reliably recognise the correct location, for example using point based feature methods such as SIFT or similar.
Our interest in this work is to consider whether similar performance can be achieve when the views are significantly disparate, for example taken further down a street, where parts of the location are visible in the different views but at considerably different scales, orientations, etc and taken at different times of the day in different weather conditions. The approach we take is based on the observation places are often characterised by distinctive landmarks such as buildings, monuments, trees, etc, and that there is evidence that humans may use such landmarks to find their way around and identify places they have previously visited. It is important to note that by landmarks we mean distinctive objects in the scene as opposed to appearance landmarks in images.
Based on this, we build representations which encode descriptions of both salient landmarks based on appearance features and the spatial configuration of the landmarks. We call these landmark distribution descriptors (LDD) and combine them with a simple matching strategy to recognise places based on a database on location views. We use EdgeBoxes to identify potential landmark regions and convolutional neural network (CNN) features find potential correspondence of landmarks between views - this component is similar to the work of Suenderhauf et al. [1].
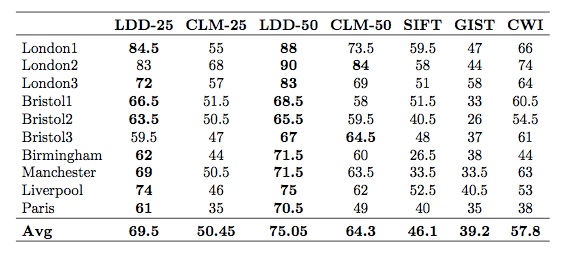
Our key contribution is to extend the method to include encode of the spatial configuration of the landmarks via the use of LDDs. This proves to have a significant impact on performance - in experiments on 10 image-pair datasets, each consisting of 200 urban locations with significant differences in viewing positions and conditions, we recorded average precision of around 70\% (at 100\% recall), compared with 58\% obtained using whole image CNN features and 50\% for the method in [1].
[1] Suenderhauf, N., Shirazi, S., Jacobson, A., Dayoub, F., Pepperell, E., Upcroft, B., Milford, M.: Place recognition with convnet landmarks: Viewpoint-robust, condition-robust, training-free. In: Proceedings of Robotics: Science and Systems, Rome, Italy (2015)
Examples of view pairs from 3 of the 6 cities in the 10 datasets used in the experiments. The pairs are shown one above the other. Note the disparity in view and also the prsence of objects such as vehicles in one view but not the other. Our dataset contains one such image pair per location - one is used as the reference image and the other is used as the test image.
Examples of correct view matches obtained using the LDD-50 method - 50 landmarks used in each LDD. Matches are shown one above the other and there are 3 matches per row.
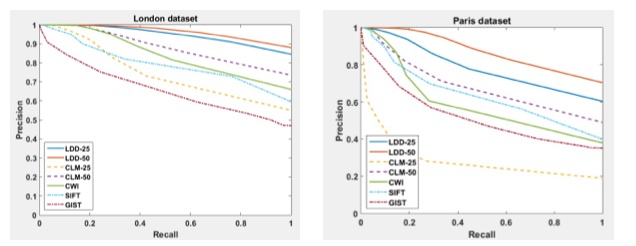
Precision recall curves obtained for all comparison methods for the London1 dataset (left) and the Paris dataset (right)
Recorded precision values for 100% recall for 10 6 city datasets with one image per location in the reference database. Our method is LDD-25 and LDD-50 with 25 and 50 landmarks per LDD, respectively, and the comparison methods are: CLM-25 and CLM-50, which are versions of that in [1] above with 25 an d 50 landmarks, respectively; CWI is a whole image method using CNN featues; SIFT is whole image point feature based matching using SIFT features; and GIST is whole image matching using global appearance GIST features.
 This work tackles the problem of place recognition - can an autonomous system recognise a particular place in a city, for instance, based on vision alone? we assume that we have one or more images of locations over a wide area and the task is to recognise places based on new images taken at the same locations but from disparate views compared with those in the database. There has been considerable work on this in the past and if images are taken from similar viewpoints then algorithms exists which are able to reliably recognise the correct location, for example using point based feature methods such as SIFT or similar.
This work tackles the problem of place recognition - can an autonomous system recognise a particular place in a city, for instance, based on vision alone? we assume that we have one or more images of locations over a wide area and the task is to recognise places based on new images taken at the same locations but from disparate views compared with those in the database. There has been considerable work on this in the past and if images are taken from similar viewpoints then algorithms exists which are able to reliably recognise the correct location, for example using point based feature methods such as SIFT or similar.
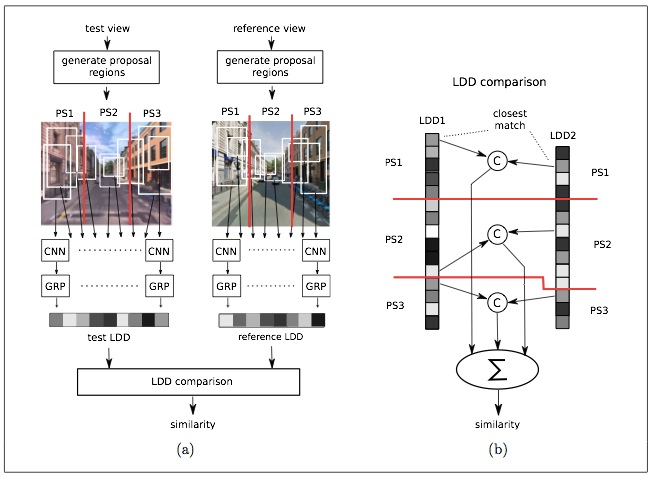 Based on this, we build representations which encode descriptions of both salient landmarks based on appearance features and the spatial configuration of the landmarks. We call these landmark distribution descriptors (LDD) and combine them with a simple matching strategy to recognise places based on a database on location views. We use EdgeBoxes to identify potential landmark regions and convolutional neural network (CNN) features find potential correspondence of landmarks between views - this component is similar to the work of Suenderhauf et al. [1].
Based on this, we build representations which encode descriptions of both salient landmarks based on appearance features and the spatial configuration of the landmarks. We call these landmark distribution descriptors (LDD) and combine them with a simple matching strategy to recognise places based on a database on location views. We use EdgeBoxes to identify potential landmark regions and convolutional neural network (CNN) features find potential correspondence of landmarks between views - this component is similar to the work of Suenderhauf et al. [1].